Using SimSANs to Study SAN Performance
1. Introduction
This page is to illustrate how the SimSANs can be utilized to study
SAN performance. Two simulation scenarios are demonstrated: one for
frame latency study discussed in
section 3, and the other is for the study of
long distance data movement discussed in section 4.
Each of the two sections presents the simulation’s configuration,
result, as well as some considerations. Section 2 outlines the
network topology that the two scenarios are running on. The
executables (for Windows), parameter configuration files, and output
data are also provided from
here.
2. Network Topology
The network topology that is used to run the scenarios is derived
from the sample network, with minor
changes involved. The first scenario (scenario 1), studying
the frame latency, uses Host 1, 2, 3, and 5 to issue sequential
write IOs to LUNs at Device1. The second scenario (scenario 2),
studying the performance of long distance data movement, uses Host 4
and 6 to issue sequential write IOs the LUNs at Device1, which then
clones the data to the mirrored LUNs at Device3 remotely located.
Figure 1 shows the network topology and the IO paths for both
scenarios, with yellow color path for scenario 1 and pink color path
for scenario 2.
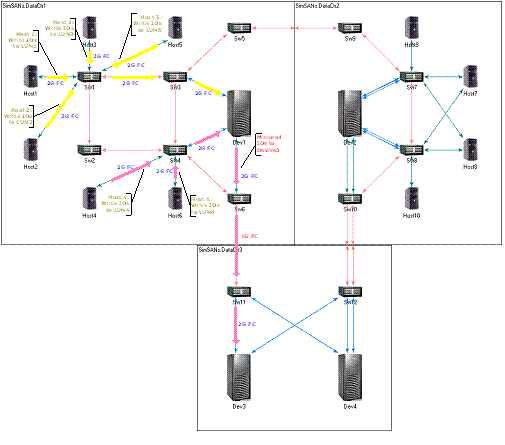
Figure 1. Network Topology and IO Paths
Click here to see the full image
3. Scenario I – Frame Latency
This scenario is to investigate the frame latency vs. concurrent
client number. Four clients (Host 1, 2, 3, and 5) are involved in
the simulation, each of which initiates 100MB sequential write IO to
a separate LUN at Device1, and IOs travel two switch hops (Sw1 and
Sw3) from Hosts to Device. Each client maintains a constant write
throughput of 40MBps during the simulation. Simulation data is
collected to analyze how the number of concurrent clients affects
the frame latency. Besides, three different IO sizes (16KB, 32KB,
and 64KB) are applied to the simulation for us to watch the effect
of the IO size on the frame latency.
Configurations
Client configuration – All four hosts have similar configurations
except that they are targeted to different LUNs. Following
parameters are configured for clients:
- Concurrent IOs: 256
- HBA Port Speed: 2Gbps
- Rx Buffer: 6
- Tx Buffer: None
- Class-3 Concurrent Sequence: 255
- Application: Sequential Write
- Application Data: 100MB
- Application Throughput: 40MBps
- IO Size: 16KB, 32KB, and 64KB
- Target LUN: LUN1, 2, 3, and 5
Switch configuration – Both switches have similar configurations.
Following parameters are configured for switches:
- Domain_ID: 101 for Sw1 and 103 for Sw3
- Port Speed: 2Gbps
- Rx Buffer: 12
- Tx Buffer: None
- Frame Forwarding: cut-through
- Forwarding Latency: around 1.88us
- Hops: 2
Device configuration – Device1 is equipped with 2 CHIPs, each of
which has four N_Ports, and only one of the eight ports is used in
the simulation. Four LUNs are setup, each of which is accessible by
one of the four clients. Except the LUN WWN, all LUNs have the same
configuration. Besides, the LUN member disks are assigned across
separate array groups to minimize resource contention. Following
parameters are configured for the device:
- CHIP Port Speed: 2Gbps
- CHIP Port Rx Buffer: 6
- CHIP Port Tx Buffer: None
- CHIP Class-3 Concurrent Sequence: 255
- Cache: disabled to avoid the cache-hit effect on the simulation
results
- ACP Array Group Number: 4
- RAID: RAID 0
- LUN Member Disks: 4
- LUN Block Size: 8KB
- LUN Stripe Depth: 32KB
- Disk Sequential Access Rate: about 25 to 40MBps
Simulation Results
Simulations were performed against different concurrent client
numbers and different IO sizes so there are total 12 separate
simulation instances scheduled, with concurrent client number of 1,
2, 3, and 4, and IO size of 16KB, 32KB, and 64KB. Figure 2 shows the
results of average network latency vs. concurrent client number.
Figure 3 shows the results of average end-to-end latency vs.
concurrent number. Figure 4 shows the average IO response time vs.
concurrent number. Network latency
denotes the duration from the time when a frame is sent out onto the
link by the source N_Port to the time when the frame is completely
received by the destination N_Port, i.e., how much time for a frame
to travel through the switch fabric.
End-to-End latency is calculated from the time the source
N_Port’s FC-2 layer initiates a frame till the time the destination
N_Port’s FC-2 layer completely receives the whole frame. It is
obvious that End-to-End frame latency includes network latency and
N_Port’s processing cost.
The simulation results show that the frame latency (both network and end-to-end) as well as the IO response time increase with the joining of more concurrent clients. This is because more concurrent clients introduce larger aggregate throughput and therefore a greater chance to cause frames piled up in the frame buffer waiting for processing. The frame latency becomes much more significant when large IO size, say, 64KB, is used since larger IO size will generate more frames at a time by Fibre Channel Sequence Segmentation so that we can expect there is a good chance of frame piling up during its traveling along the IO path.
Considerations
Basically the simulation results reflect the frame latency behavior
that a SAN environment usually presents. Please note this simulation
is just a demonstration of utilizing SimSANs to study the frame
latency issue. In fact, there are many factors that can affect frame
latency including Rx/Tx buffer settings, link speed, concurrent
IO/Sequence values, N_Port processing cost, switch processing cost,
IO pattern, application throughput, network topology, and so on. To
thoroughly investigate latency issue more advanced scenarios against
real-world cases/test-beds can be modeled and simulated in SimSANs
by taking into account the combination effect of many of those
factors.
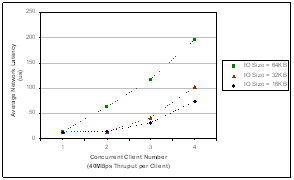
Figure 2. Average Network Latency vs. Concurrent Client Number
Click here to see the full image
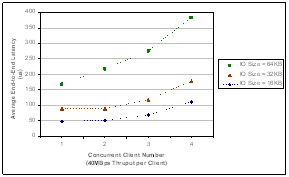
Figure 3. Average End-to-End Latency vs. Concurrent Client Number
Click here to see the full image
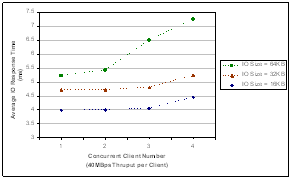
Figure 4. Average IO Response Time vs. Concurrent Client Number
Click here to see the full image
4. Scenario II – Long Distance Data Movement
This scenario is to investigate the application throughput for the
data movement over long distance, such as remote mirroring,
replication, or cloning, etc. Two clients (Host 4 and 6) are
involved in the simulation, each of which simultaneously initiates
100MB sequential write IO to a separate LUN at Device1, and Device1
then initiates remote mirroring operation (say, by using extended
copy or thirty-party copy) to copy the data to remotely located
Device3 through Sw6 and Sw11. Please refer to figure 1 for the
network topology and IO path. The sustained throughput of the
mirroring operation is recorded. The larger the throughput is, the
better the performance.
Simulation Configurations and Results
Most of the configurations of hosts, switches, and devices are
similar to those used in scenario 1 except for the followings:
- ISL between Sw6 and Sw11: 1Gbps link speed, large BB_Credit (or Rx
buffer)
- Distance between Sw6 and Sw11: 1786km
- Target LUN: LUN4 and LUN6 accessible by Host4 and Host6
respectively
- LUN Block Size: 64KB
- LUN Stripe Depth: 256KB
The recorded mirroring operation throughput is 97.29 MBps.
Considerations
The simulation takes on the form of direct ISL connection between Sw6 and Sw11 without considering an intermediate network, say, IP network, between them. With the implementation of iFCP/iSCSI in the future version of the SimSANs, we can be able to study the performance of Fibre Channel SAN extension over IP network. Considering the protocol overhead introduced by iFCP/iSCSI/TCP/IP one can expect that the application throughput of the data movement over IP SAN will be a little bit lower than the one of the above simulation which uses a direct FC ISL.
This page was last updated 2003.11.25